En un mundo donde las máquinas conversan, razonan y actúan, el ecosistema de inteligencia artificial se transforma a velocidad de vértigo. Este artículo explora quiénes mueven el tablero y cómo diferentes modelos de agentes se comportan en escenarios reales, con mirada crítica y práctica.
Ecosistema de IA: panorama y actores clave
La primera capa del ecosistema la constituyen los grandes proveedores de modelos y plataformas: empresas como OpenAI, Google, Microsoft y Anthropic que entrenan LLMs a gran escala y ofrecen APIs, infraestructuras y herramientas de integración. Estas organizaciones definen en gran medida estándares de rendimiento, políticas de seguridad y modelos comerciales que marcan el ritmo de adopción en sectores como finanzas, salud y entretenimiento.
Paralelamente existe un pujante universo de proyectos open source y startups especializadas que impulsan la innovación horizontal: Llama, Mistral, Hugging Face y comunidades de investigación que democratizan pesos, tutores y herramientas para crear agentes personalizados. Su aporte clave es la flexibilidad —permitiendo ajustar, auditar y desplegar soluciones en entornos regulados o con restricciones de privacidad— y la diversidad de aproximaciones técnicas.
Finalmente, el ecosistema incluye a actores no tecnológicos pero críticos: reguladores, clientes empresariales y usuarios finales. Normativas sobre datos, auditorías de sesgo, necesidades operativas y expectativas éticas configuran qué agentes prosperan. La interacción entre la capacidad técnica y el marco sociolegal determinará si una solución es viable más allá de una prueba de concepto.
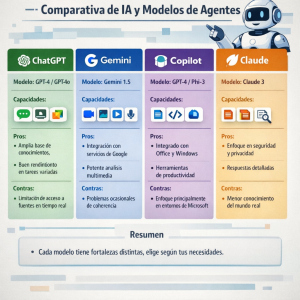
Comparativa práctica: modelos de agentes en acción
Para evaluar agentes en la práctica conviene comparar criterios como integrabilidad con herramientas (APIs, bases de datos, navegadores), latencia y coste por consulta, capacidad de razonamiento encadenado, y garantías de privacidad y explicabilidad. Por ejemplo, agentes comerciales suelen ofrecer integración out-of-the-box y soporte, mientras que soluciones open source permiten despliegues on-premise y control total de datos a costa de mayor esfuerzo de ingeniería.
En escenarios concretos —soporte al cliente, asistente de investigación y automatización de workflows— los agentes difieren: modelos orientados a diálogo gestionan mejor matices conversacionales y satisfacción del usuario; arquitecturas con memoria y recuperación semántica sobresalen en tareas investigativas; y agentes diseñados para orquestación (ej. frameworks como LangChain o sistemas de herramientas de Anthropic/OpenAI) agilizan automatizaciones que requieren llamar APIs y manipular estados. Cada enfoque implica trade-offs entre precisión, coste y robustez.
Desde una perspectiva operativa, la elección debería basarse en el riesgo y el valor esperado: para casos que demandan alta fiabilidad y cumplimiento normativo, priorizar modelos auditables y despliegues privados; para prototipos y experimentación, favorecer integraciones rápidas con modelos en la nube; y para soluciones de alto volumen, optimizar por latencia y coste por consulta. La recomendación práctica es diseñar pruebas de concepto con métricas claras (tiempo de respuesta, tasa de error, satisfacción del usuario) y iterar hacia despliegues mixtos que combinen modelos comerciales y componentes open source según necesidad.
El ecosistema de IA es un mosaico dinámico: actores con diferentes incentivos, tecnologías complementarias y desafíos regulatorios que exigen decisiones informadas. Entender las capacidades y límites de los modelos de agentes permite seleccionar estrategias equilibradas entre innovación, coste y responsabilidad.